The ReAl Computer Architecture
Principles of Operation
|
|
|
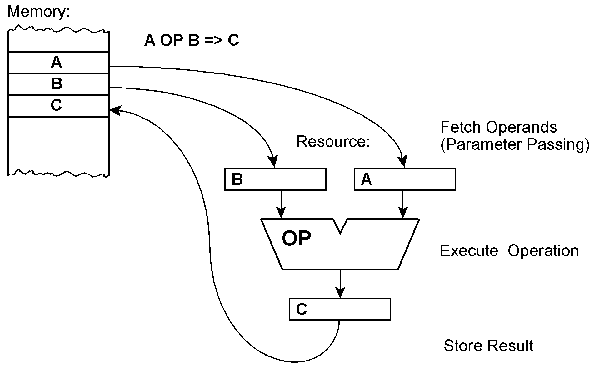
The Computational Model Operators and Parameters The ReAl architecture supports the exploitation of an arbitrary number of arbitrary resources. Fig. 1 illustrates how a single resource is be used according to the ReAl computational model. In the example, the following steps are executed:
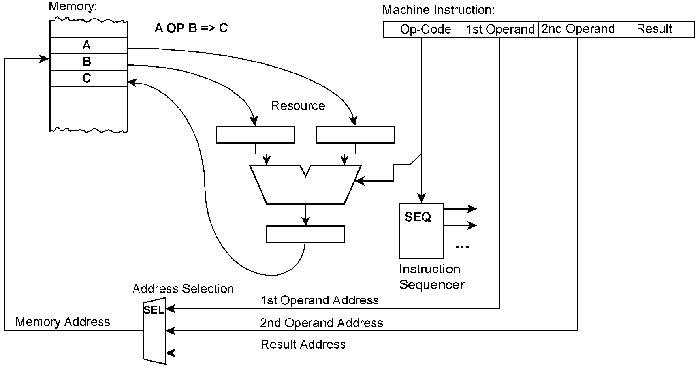
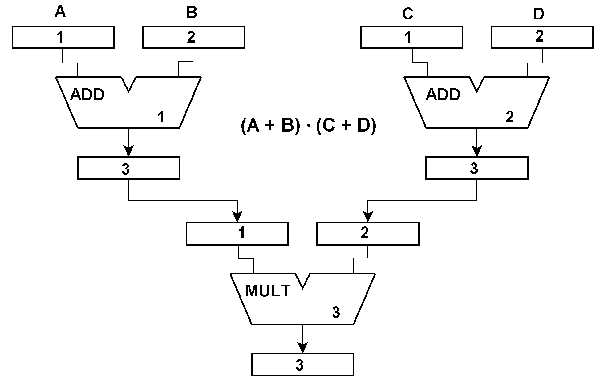
Fig. 1 How a single resource is used – the basic computational model. When only one resource is considered, especially one that has only a few parameters and executes only well-known basic operations, there is virtually no difference to conventional computer architectures (fig. 2). It is merely the question whether the consecutive processing steps are controlled implicitly by the control unit (instruction sequencer) or explicitly by appropriate encoded commands. In this respect the ReAl architecture bears some resemblance to the principles of vertical microprogram control. The peculiar ReAl benefits however will come into effect when more than one resource is exploited and when the ReAl principles of operation are applied to the program as a whole. Concatenation Resources can be combined to complex arrangements. Such a configuration corresponds to the data flow diagram of the respective processing operations (fig. 3). The ReAl computational model implies provisions for connecting resources according to data flow diagrams and for disconnecting again these connections. In the following, such connections will be referred to as concatenations. Fig. 2 For comparison: instruction execution in a conventional processor.
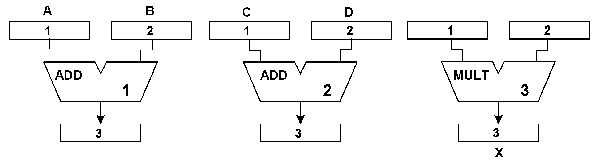
Fig. 3 A basic example of resources combined according to a data flow diagram: three resources have been concatenated to calculate (A + B) • (C + D). The basic ReAl Operators In a ReAl machine, the processing steps are controlled by stored instructions. The abstract (machine-independent) instructions are referred to as operators. There are at least eight basic types: 1. Select resources: s-operator. 2. Establish concatenations between resources: c-operator. 3. Feed resources with operands from memory (parameter passing): p-operator. 4. Initiate the information processing operations: y-operator (yield). 5. Move data between resources: l-operator (link). 6. Assign results (to variables in memory) : a-operator. 7. Disconnect concatenations: d-operator. 8. Return resources to the resource pool: r-operator. Some basic variants:
Parameter passing The data with which the resources work are generally referred to as “parameters”. Input parameters are also referred to as operands; output parameters are referred to as results. Thre are three types of parameters:
Parameters are passed in general by value. If this is not easily possible, additional resources (for example, addressing respources) must be provided in order to fetch and move the values. Additional operators In practice, additional operations are to be initiated and additional information is to be passed to, for example, for supporting compilers, for system administration and the like. In order to be able to provide such supporting functions in a way consistent with the basic principles of operation, some supplemental operators are introduced: 1. Hints: h-operator. 2. Meta-language support: m-operator. 3. Administrative and auxiliary functions: u-operator (utility). Denotation of ReAl Program Operations ReAl programs are essentially sequences of operators. ReAl program operations can be represented as follows:
In the following descriptions a simple text code will be employed. The basic syntax:
ordinal number : symbolic name.
operator_ name = s | c | p | y | l | a | d | r | h | m.
resource . parameter.
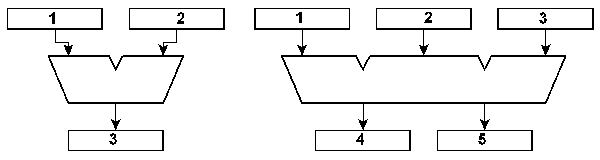
Fig. 4 Resources with enumerated parameters. Assignment of symbolic names:
Assign resource type name: u_tn. u_tn (ordinal number : symbolic name). Rename resource type: u_trn. u_trn (previous symbolic name : new symbolic name).
Assign parameter name: u_pn. u_pn (ordinal number : symbolic name). Rename parameter: u_rrn. u_prn (previous symbolic name : new symbolic name).
Assignment in the parameter string of the s-operator: resource type : symbolic name. Assign resource name: u_rn. u_rn (ordinal number : symbolic name). Rename resource: u_rrn. u_rrn (previous symbolic name : new symbolic name). Basic Operators 1. Select resources: s-operator s (list of resource type identifiers) s (1st resource type, 2nd resource type an so on) The s-operator is used to request resources of certain types out of the resource pool. The effect of a s-operator depends on the requested resources as well as of the kind of the underlying hardware: An appropriate hardware resource (in other words, a function unit (like an ALU)) is reserved, initialized and assigned. Appropriate memory areas are reserved, initialized, and assigned. Optionally, the respectively required control information is loaded (programs, microprograms, net lists, Boolean equations and the like). The requested resource is built from other resources (recursion). An appropriate hardware structure is generated, for example, by programming cells and connections on a programmable integrated circuit. Initializing a resource means to set up literals and initial values, to adjust the data width, to load control information (like microprograms) and so on. Assigning a resource means to incorporate it into the administration of the selected resources so that it can be accessed by subsequent operators under ordinal number or by addressing. Resource type identifiers For conventional (generic) resources, the resource type identifier is the appropriate type designator (as given, for example, in the particular reference manual). Special resources are designated by their particular symbolic name. Generally, Internet addresses and the like can also be used as identifiers. Enumeration of resources The requested resources are enumerated consecutively. Subsequent operators then refer to the selected resources by those ordinal numbers (or by the assigned symbolic names). 2. Establish concatenations between resources: c-operator c (list of concatenations) c (1st source resource . 1st result => 1st destination resources . 1st parameter, 2nd source resource . 2nd result => 2nd destination resource . 2nd parameter and so on) Concatenation means to connect an output (result parameter) of the source resource with an input (operand parameter) of the destination resource. The c-operator loads concatenation control information (like address pointers) into the resources). In some implementations the operator will initiate the setup or programming of appropriate physical connections (for example, within a switch fabric or an FPGA). If concatenation is exploited to the extreme, the concatenated resources constitute a structure which corresponds to the dataflow graph of the application problem. Input concatenation When supported appropriately, it is possible to concatenate inputs with one another (input concatenation). Such a concatenation corresponds to connecting corresponding inputs in parallel. Application: for supplying simultaneously parameters to several resources. 3. Feed resources with operands (parameter passing): p-operator p (source-to-destination list). Source are variables in system memory or the like, destinations are parameters of resources. p (1st variable => resource . parameter, 2nd variable => resource . parameter and so on) The p-operator moves the specified variables (for example, from system memory or an I/O address space) into the specified operand parameter positions of the specified resources. The variables are designated by names, ordinal numbers or addresses. In resources that support concatenation appropriately, p-operators can also initiate the execution of operations (processing begins when all operands are valid). 4. Initiate the information processing operations: y-operator y (list of resources) y (1st resource, 2nd resource and so on) A y-operator initiates the execution of operations in the specified resources. What the respective resources will do, depends on directly from the type of resource (when it can perform only a single function) or on parameters (function codes) that have to be set beforehand (for example, by means of s-operators or p-operators). An alternative method of operation initiation – without a y-operator – can be applied when the resource supports concatenation. The execution of an operation will be initiated if all required operands are valid. Valid operands can be supplied by means of p-operators or l-operators or by concatenation. Contrary to conventional instruction sets, the selection of the operation to be executed (s-operator) has been separated from the initiation of the operation (y-operator or concatenation). Hence the resources know in advance for which purpose the operands are destined. The initiator code (within y-operators) is typically shorter than a conventional operation code. This avoids instruction traffic during execution and can be an advantage if more than one function is to be initiated (appropriately formatted y-operators can initiate more operations simultaneously than conventional instructions of same length). 5. Move data between resources: l-operator l (source-to-destination list). Sources and destionations are parameters of resources. l (1st source resource . 1st result => 1st destination resource . 1st parameter, 2nd source resource . 2nd result => 2nd destination resource . 2nd parameter and so on) The l-operator moves parameters between the specified resources (from the output (result parameter) of the source resource to the input (operand parameter) of the destination resource, respectively). In resources that support concatenation appropriately, l-operators can also initiate the execution of operations (processing begins when all operands are valid). 6. Assign results: a-operator a (source-to-destination list). Sources are parameters of resources, destinations are variables in system memory or the like. a (1st resource . 1st result => 1st result variable, 2nd resource . 2nd result =>2nd result variable and so on) The a-operator moves the contents of the specified result parameter positions of the specified resources to the specified variables (for example, in system memory or in an I/O address space). The variables are designated by names, ordinal numbers or addresses. 7. Disconnect concatenations: d-operator d (list of concatenations) d (1st source resource . 1st result => 1st destination resource . 1st parameter, 2nd source resource . 2nd result => 2nd destination resource . 2nd parameter and so on) The d-operator disconnects existing concatenations. In some implementations (for example, in FPGAs) it can cause the corresponding physical connections to be changed or cut off (by reprogramming). Disconnected resources can be used separately or can be concatenated again. 8. Return resources to the resource pool: r-operator r (resource list) r (1st resource, 2nd resource and so on) The specified resources are returned to the resource pool. They are therefore available to be used for other processing tasks. Basic Examples The following example illustrates how a programming intention can be implemented. The programming intention: to compute X := (A + B) • (C + D). Available resource types: ADD, MULT. Fig. 5 illustrates the corresponding resource configuration comprising two adders (ADD) and a multiplier (MULT). The ordinal numbers of the resources: first adder = 1, second adder = 2, multiplier = 3. The ordinal numbers of the parameters of a resource: inputs (operands) = 1 and 2, result = 3. Fig. 5 A resource configuration to compute X := (A + B) • (C + D). The notation at full length (each step individually): s (ADD) s (ADD) s (MULT) p (A => 1.1) p (B => 1.2) p (C => 2.1) p (D => 2.2) y (1) y (2) l (1.3) => 3.1) l (2.3 => 3.2) r (1,2) y (3) a (3.3 => X) r (3) An abbreviated notation: s (ADD, ADD, MULT) p (A => 1.1, B => 1.2, C => 2.1, D => 2.2) y (1, 2) l (1.3 => 3.1, 2.3 => 3.2) r (1, 2) y (3) a (3.3 => X) r (3) The resources connected according to the data flow (concatenation; refer to fig. 3): s (ADD, ADD, MULT) c (1.3 => 3.1, 2.3 => 3.2) p (A => 1.1, B => 1.2, C => 2.1, D => 2.2) y (1, 2, 3) -- begin of processing in the concatenated resources a (3.3 => X) r (1, 2, 3) The y-operator is not needed when the resources support an appropriate advanced concatenation mode. Some additional operators 1. Select a resource and assign a particular ordinal number: s_a-operator s_a (list of pairs resource type identifier => resource ordinal) s_a (1st resource type => 1st resource ordinal, 2nd resource type => 2nd resource ordinal and so on) This variant of the s-operators assigns particular ordinal numbers to the requested resources. Depending on the implementation, similar operators can be provided to assign addresses in a resource address space instead of the ordinal numbers. 2. Load immediate values (literals) into resources: p_imm-operator p_imm (list of pairs literal => destination). The destinations are parameters of resources. p (1st literal => resource . parameter, 2nd literal => resource . parameter and so on) The p_imm-operator moves immediate values (literals) into the specified operand parameter positions of the specified resources. In resources that support concatenation appropriately, p_imm-operators can also initiate the execution of operations (processing begins when all operands are valid). 3. Initiate selected functions: y_f-operator y_f (list of pairs resource . function code) y_f (1st resource . 1st function code, 2nd resource . 2nd function code and so on) A y_f-operator initiates the specified functions in the specified resources. This variant contradicts the principle of encoding in the operators only the most basic processing steps but not concrete machine operations. It is some kind of stopgap minimalist solution (suitable, for example, for small FPGAs, microcontrollers and the like). 4. Provide hints to support speculative activities: h-operator Hints (h-operators) can cause variables or program pieces to be loaded speculatively into cache memories so that, when required, they are already available). Additional h-operators can be provided in order to indicate future demand in regard to certain resource types or certain configurations of resources. Such hints can be used, for example, to select such resources out of the resource pool which are, in regard to a subsequent concatenation, conveniently located on the integrated circuit. 5. Provide information for compiling and other activities of program generation: m-operator Meta-language operators (m-operators) concern the setup of resource configurations, the conditional execution of ReAl programs and the like. Such operators are similar to the pre-processor and compiler directives of conventional programming languages. However, they can become active not only at compile time but also at run time. A typical application: as a function of which resource types are available, one of several alternative branches of a ReAl program is selected in order to execute a certain programming task. Conventional conditional branches depend on processing results, operand values and so on. Meta-language caused branching depends, for example, on the type and number of available resources. The m-operators can access and change the contents of the table structures of resource administration. 6. Auxiliary and aministrative functions: u-operator All those functions that are required during program execution but cannot be encoded with operators s, c, p, y, l, a, d, r, h, m are encoded with u-operators (in other words, u-operators are some kind of stopgap provision). Implementation of h-, m- and u-operators The functions that are encoded with h-, m-, and u-operators can be provided by means that are outside of the resource pool. This can be, for example, a conventional general-purpose computer that administers and controls the pool of processing resources. Appropriate functional units are generally referred to as platforms. Alternatively, it is possible to specifically provide for many of these functions additional resources or to configure, based on already present resources, corresponding resource arrangements ad hoc, for example, resources that fill speculatively cache memories, reserve other resources, or administer resource tables. Basically, the platform outside of the resource pool can be restricted to the most elementary functions of instruction fetch, initialization and the like. All other functions can be implemented by basic ReAl operators employing a sufficiently equipped resource pool. Therefore, a more precise description of the h- and m-operators is not required here. Some u-operators will be explained in more detail when necessary. Operators and Instructions
ReAl and Conventional Programming Languages Fundamentally, ReAl programs can be likened to manufacturing or machining instructions) – ReAl programming means just to plan ahead. Which manufacturing steps are to be executed? Which tools and machines are necessary? Which part has to be supplied to which machine in the course of time? No engineer would begin designing cars, ships and so on writing down instructions of this kind. Analogously, a programmer will not use a ReAl text code for jotting down his programming ideas. Instead, ReAl programs will be generated automatically from source programs written in higher-level languages. Machine-independent ReAl codes can be seen as intermediate languages, similar to the well-known Java byte code (table 1). However, the goal is not code compactness but to describe precisely the inherent parallelism and essential intricacies of program operation. In this respect, ReAl may be better compared to Postscript than to Java. Some variants related to compiling and program execution:
Table 1 Java Virtual Machine (JVM) vs. ReAl.
|
|
|
|