The ReAl Computer Architecture
ReAl = Resource Algebra
|
|
|
Cores or resources?
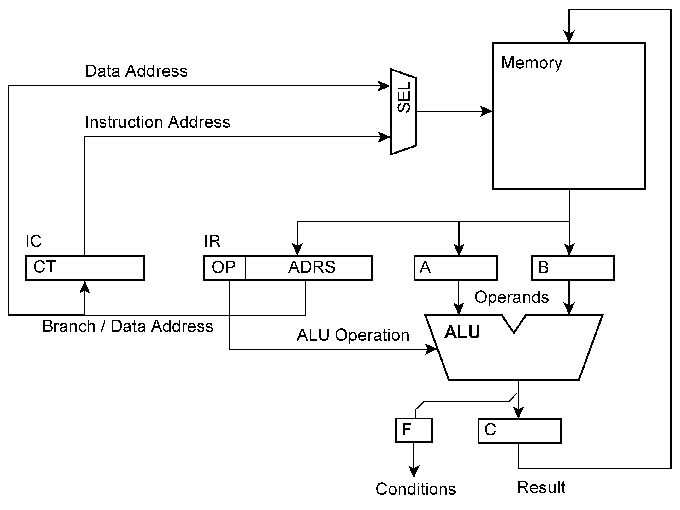
This block diagram shows a very basic processor core. A processor is an autonomous state machine. The next state depends on the current memory content. However, a word in memory can influence the state transition only if it is selected by an instruction or data address, respectively. To take advantage of multiple cores, they must not only be supplied with work (parallelization), but it is also necessary to coordinate the particular programs running (synchronization). Synchronization means to observe and modify the stream of instructions from outside of the processor core. The problem is to find appropriate points of intrusion.
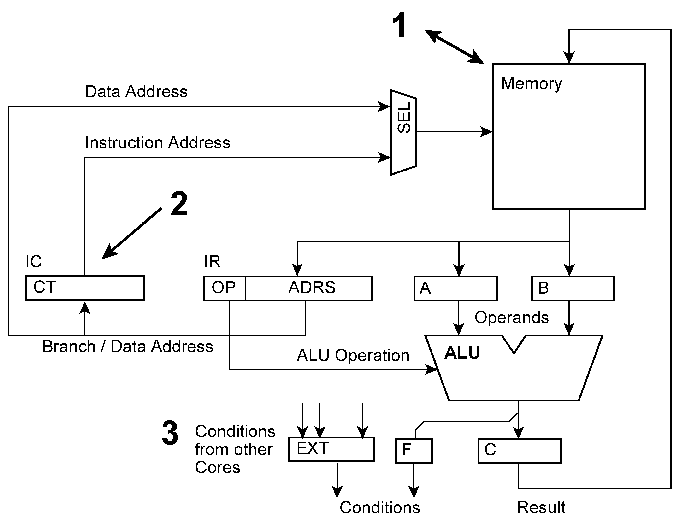
1 - read and modify the memory content. The memory needs two access paths. This method will cost either time (multi-master bus system or another kind of memory arbitration) or silicon real estate (dual-port organization). The latencies are high, because modified memory words will be effective only if addressed by the program. 2 - read the instruction address and enforce the execution of appropriate instructions. The former can be done with comparator circuitry, the latter by triggering interrupts, inserting instruction addresses and the like. To work effectively, the machine must have no pipelines, especially no extraordinarily deep ones. 3 - signal conditions to and evaluate conditions from other cores. The circuitry is simple, but requires special instructions. The latencies are comparatively high. When some cores have to do much and the other little, the system is not evenly loaded. There are numerous proposals to do something useful with unemployed cores, like executing instructions speculatively or using their memory capacity as some kind of cache extension. However, such countermeasure will be effective only with a certain probability. If they are not effective, they are basically wasting machine cycles and hence power. Power avoiding unnecessary signal transitions, too. A true optimum solution would be a machine whose cycles contribute exclusively to compute the desired final results (efficiency of implementation).it always processor? The basic alternative: the internal loop of instruction addressing and fetching will be broken. Software does not synchronize autonomous state machines. Instead, it will control a fabric of comparatively basic resources, like arithmetic logic units and address calculation units. .
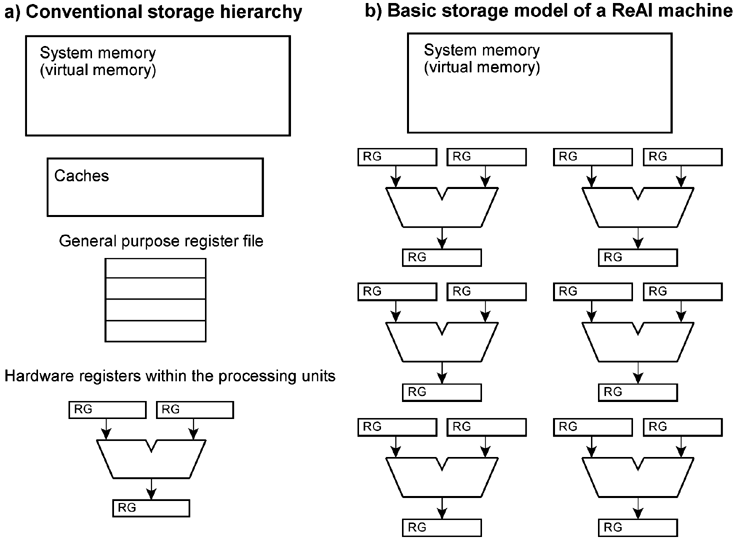
In a conventional storage hierarchy, the instructions will cause variables to be moved around (from the general purpose register file into the hardware registers and back, from the caches into the general purpose register file and back). This will cause transients on signal lines and hence power consumption. In a ReAl machine, variables and control codes reside within the processing resources. Only results are to be forwarded. It's time to try out something really new . . . Contemporary processor architectures are based on principles developed in the seventies and eighties. In those times hardware was scarce. All design decisions (which architectural ideas are to be implemented and which not) had to consider the limits of technology (like maximum number of transistors, available silicon real estate and so on). Today's semiconductor technology, however, is able to provide more than one high-performance processor core on a single piece of silicon. In our opinion, the progress of semiconductor technology should be used not only to implement processor cores of well-known vintage, but also to try out something radically new . . . What about further development of conventional processor architectures? - Such attempts could be successful, of course. But . . . In real life, the performance has been enhanced mainly by means of technology (more transistors, more GHz, smaller geometries and so on). Only a few architectural ideas have had a true decisive influence. The miracles are done by the silicon, by the compilers, and by the algorithms. Compared to technology, the majority of architectural improvements have only modest effects.
Hence we will pursue another approach. The principal hypothesis could not be more simple: There will always be enough . . .
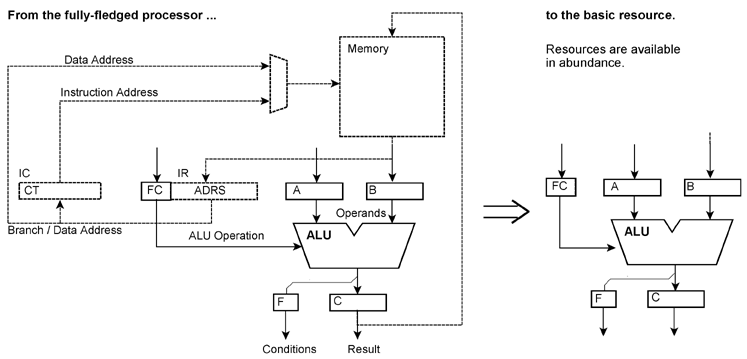
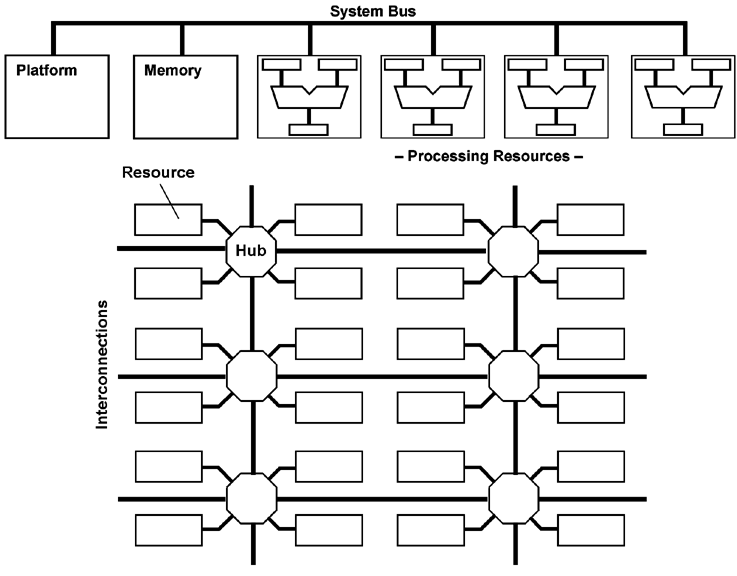
Our basic paradigm: If we want to do something, we will fetch an appropriate piece of hardware out of a magazine (like a hammer to drive in a nail or a wrench to fasten a nut) and use it to perform the information processing task to be executed. If we want to add two numbers together, we take an adder, if we want to compare two values, we take a comparator and so on. A piece of hardware which has done its duty will be returned to the magazine. We will take as many tools as we need, for example 50 hammers if 50 nails are to be driven in, or 50 adders if 50 pairs of numbers are to be added together. Our architectural definition is based on a set or pool of resources which can execute certain operations with data of certain types. This constitutes basically an algebraic structure. Hence the name ReAl = Resource-Algebra. The basic model of a resource is a hardware unit (like an adder or a universal ALU) performing certain information processing operations. The ReAl architecture is based on the following principles:
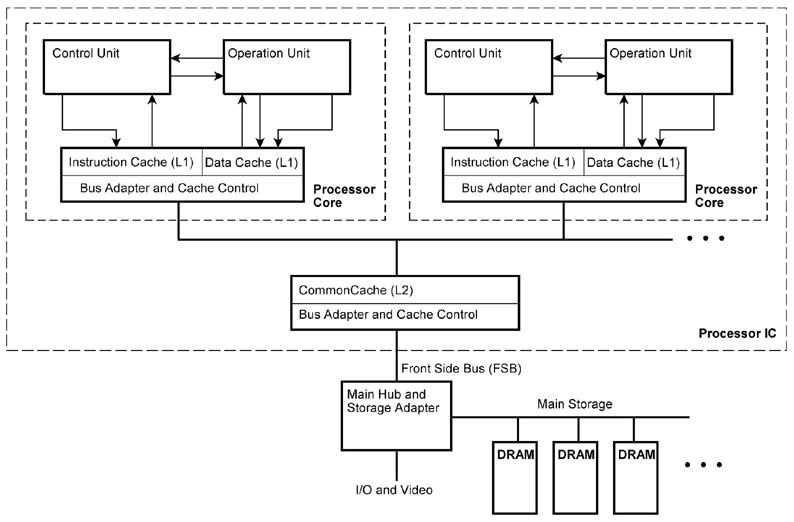
In order to implement a certain programming intention, appropriate resources will be selected out of the resource pool. These resources will be fed with parameters. Then the processing operations will be initiated. Results will be stored in memory or written to I/O devices; intermediate results will be forwarded to other resources. Further steps of parameter passing, initiation and assignment will be executed until the processing task has been completed. Resources which are no longer needed will be returned to the resource pool. These processing steps are controlled by stored instructions. So-called platform resources are provided to fetch the instructions from memory. Additional instructions are provided to establish connections between resources (to concatenate resources) and to disconnect such concatenations. Once a concatenation has been established, the steps of parameter passing, initiation of operations and assignment of results will be performed automatically; there is no need to control each single processing step by separate instructions. The steps of parameter passing, operation initiation and so on can be applied to hardware as well as to software. Program and hardware resources are invoked the same way. Each program or subroutine corresponds to the model of a hardware with input and output registers (register-transfer model). If these principles are applied to the last extreme, machine program generation will be transformed into hardware design. Starting with the source code, a special hardware will be designed which is able to execute the application problem in question. This virtual hardware can be created, modified and dismantled during runtime. If a resource is not available as a true hardware unit, its operation can be performed by means of other resources by applying the very method (recursion) or by conventional programs (emulation). A rough estimate: On an integrated circuit with 200 million transistors, it would be possible to arrange four superscalar processor cores, each having approximately 50 million transistors. The operation units of such a processor correspond roughly to eight 64-bit arithmetic/logic units (the differences between integer and floating point units being neglected here). These 4 cores • 8 operation units correspond to 32 resources. The instruction fetch and execution control hardware is to be replaced by ReAl platform circuitry. Cache memories, control circuits, and bus systems are maintained (same size, but modified structure). Some more resources could be located on the silicon area otherwise occupied by additional circuitry (pipelining, detection of hazards and so on). Therefore, one can reasonably expect a processor IC containing approx. 48 to 64 high-performance processing resources. Our goal may be illustrated by a ReAl game console processor which can be morphed on the fly into a graphics engine, an AI engine, a physics engine and so on, depending on the requirements of the game being played. The ReAl architectural principles can be used for various other purposes, too. Examples may be a machine-independent intermediate language (similar to the well-known Java bytecode (Table 1)) or a compiling method to detect inherent parallelism.
Table 1 Java Virtual Machine (JVM) vs. ReAl. (Note: As the goal is not code compactness but to describe precisely the inherent parallelism and essential intricacies of program operation, ReAl may be better compared to Postscript than to Java.) |
|
|
|
July 1, 2026 *** America 250 *** *** Happy 4th of July *** Resource Algebra Vol 2 (in German)
Resource Algebra Vol 1 (in German)
Article in Circuit Cellar, December 2016: Resource Algebra and the Future of FPGA Technology For viewlng and downloading (PDFs): Introduction (25 Pages) IDAACS 2007 Presentation (PDF) Resources instead of Cores? – Article in ACM Sigarch Computer Architecture News, Volume 38, Number 2, May 2010, pages 49 – 63. Excerpt: Section 4 – A metrics of efficiency (PDF) A detailed preliminary description (PDFs): 2. The ReAl Computational Model 3. Platform Architecture 4. ReAl Machines In German: A preliminary description (Vorlaeufige Kurzbeschreibung) (120 Pages) Patent Applications:
|